
「ChatGPTは使いたいが、社内データを外に出せない」という壁
社内にAIを導入したい企業の多くがぶつかるのが、データ主権と情報漏洩のリスクです。顧客情報・見積もり・契約書・議事録──これらを ChatGPT や Gemini に入力して活用したいが、外部SaaSに送るわけにはいかない、というジレンマは業種を問わず存在します。
2026年4月3日、国立情報学研究所(NII)は約12兆トークンで学習した日本語特化LLM「LLM-jp-4」 の 8B モデルと 32B-A3B(MoE)モデルをオープンソースライセンスで公開しました。これは、自社サーバー内だけで動く日本語プライベートAI基盤を持つという選択肢が、中小企業にとっても現実的になったことを意味します。
本記事では、LLM-jp-4 の特徴と、社内LLMとして導入する際の実務的な設計ポイントを整理します。
LLM-jp-4 の特徴
日本語特化・大規模学習
LLM-jp-4 は、NII 主導で進められている LLM-jp プロジェクト の第4世代にあたるモデルです。前世代比で学習データ・パラメータ数が大幅に増え、日本語ベンチマークで商用モデルに迫るスコアを出しています。
| 項目 | LLM-jp-4 8B | LLM-jp-4 32B-A3B |
|---|---|---|
| アーキテクチャ | Dense Transformer | Mixture of Experts(MoE) |
| 学習トークン数 | 約12兆 | 約12兆 |
| 推論時アクティブパラメータ | 8B | 約3B |
| ライセンス | オープンソース(商用利用可) | 同上 |
| 想定用途 | エッジ・低コスト推論 | 高精度・業務特化 |
なぜ「国産」が重要なのか
英語圏の OSS モデル(Llama 4、Qwen、Gemma 4 など)も日本語を扱えますが、以下の理由で国産モデルが優位になるケースがあります。
- トークナイザーの効率:日本語テキストを英語ベースモデルより少ないトークン数で処理できる → 推論コストが下がる
- 法令・公文書・業務用語の精度:日本語データで学習しているため、商慣習・法令文・業務定型文での出力が安定
- データガバナンス:完全に国内完結で運用できるため、個人情報保護法・業界別ガイドラインへの対応が容易
オンデバイスLLMの潮流についてはGemma 4 完全ガイド、国産LLMの競合比較はGemma 4 × Qwen × Granite 比較も併せてご覧ください。
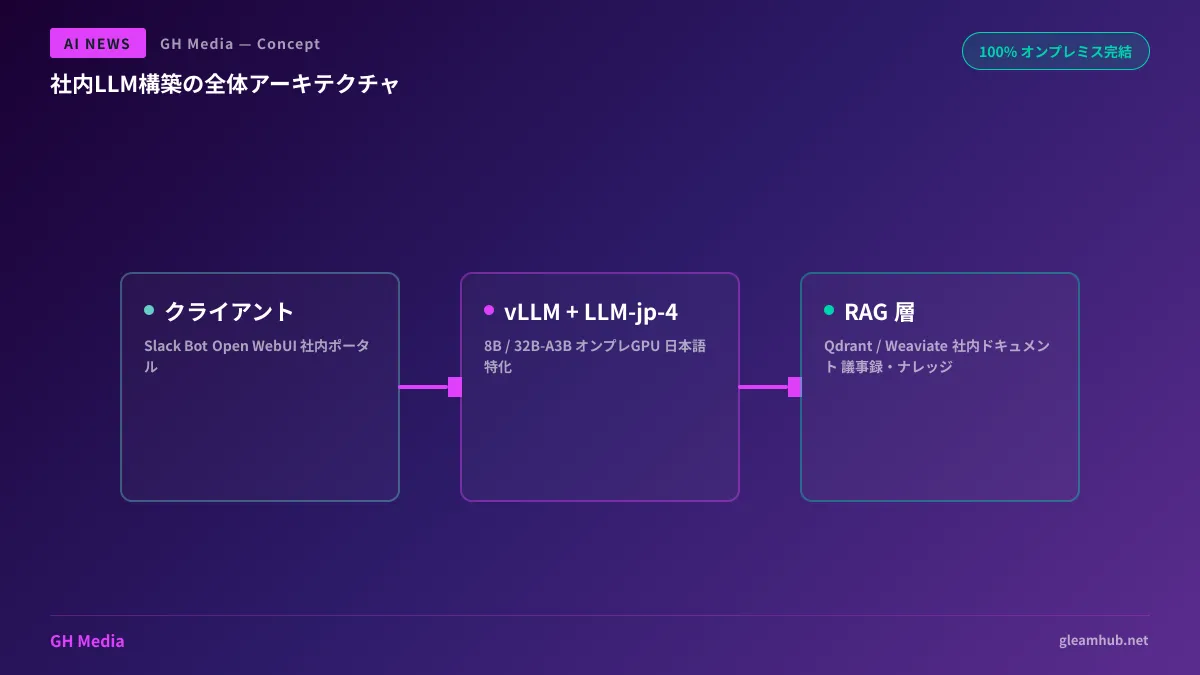
社内LLM構築のアーキテクチャ
最小構成(オンプレ1台)
中小企業が最初に試す構成としては、以下のようなシンプルなスタックが現実的です。
| レイヤー | 技術選定例 |
|---|---|
| ハードウェア | GPUサーバー 1台(RTX 6000 Ada もしくは H100 1枚) |
| 推論エンジン | vLLM / Ollama / TGI |
| モデル | LLM-jp-4 8B(または 32B-A3B) |
| フロントエンド | Open WebUI / 自社Slackボット |
| RAG | LlamaIndex + ベクトルDB(Qdrant / Weaviate) |
この構成であれば、初期投資数百万円・月額数万円の電気代で、20〜50人規模の社内利用を賄えます。
RAG 連携が本命
LLM 単体では「社内ナレッジに詳しいAI」にはなりません。社内ドキュメント・議事録・ナレッジベースをRAG(Retrieval-Augmented Generation) で接続することで、真の意味での「社内AIアシスタント」になります。
RAG 設計のパターンは2026年版 RAG 最適化パターン、MCP を使った外部連携はMCP 完全ガイドで詳しく解説しています。
導入フェーズの進め方
フェーズ1:検証PoC(1〜2ヶ月)
まずは特定業務・特定部門に絞ってPoCを走らせます。
- GPUサーバー1台を社内に配置し、LLM-jp-4 8B を vLLM で起動
- 社内Wiki・議事録20〜30ファイルをベクトル化して RAG 接続
- 1部門(5〜10人)で日常業務に使ってもらう
- 利用ログ・満足度・誤答事例を収集
フェーズ2:業務特化チューニング(2〜3ヶ月)
PoC で得られたフィードバックを元に、業務特化のアダプタ学習(LoRA / QLoRA)を実施します。
- 自社の文書体系・用語辞書を教師データ化
- NG回答・必須回答フォーマットをプロンプトエンジニアリング
- 誤答パターンを評価セット化して回帰テスト
フェーズ3:全社展開(3〜6ヶ月)
利用者層を広げ、SSO 連携・アクセス権限・監査ログを整備します。この段階からは、セキュリティと運用監視が主テーマになります。セキュリティ設計全般はWebセキュリティ基礎も参考にしてください。
よくある落とし穴
- 「OSSだから無料」という誤解 — モデル自体は無料でも、GPU・電気代・運用工数が発生します
- RAG の精度過大評価 — 社内ドキュメントが散在・重複している状態では、RAG は逆に混乱します。ナレッジ整備が先です
- ハルシネーション対策不足 — 社内用途であっても「もっともらしい嘘」は発生します。回答の根拠表示を必須化しましょう
- 運用担当の不在 — モデル更新・評価・プロンプト改善を継続する人員を社内に置くか、外部パートナーに伴走してもらう必要があります
まとめ
NII「LLM-jp-4」の登場は、日本企業が自社でLLMを持つ時代の分水嶺になる可能性があります。
- 意義:外部SaaSに依存しないプライベートAI基盤が現実的に
- 最小構成:GPU1台 + vLLM + RAG + Open WebUI で20〜50人規模を賄える
- 成功要因:ナレッジ整備・RAG設計・評価サイクル・運用担当
- 投資対効果:初期数百万円・月額数万円で、ChatGPT Enterprise 相当の体験を自社内で構築可能
「社外にデータを出せないから ChatGPT を諦めていた」という企業こそ、LLM-jp-4 はゲームチェンジャーになり得ます。
グリームハブでは、中小企業向けのプライベートLLM構築・RAG設計・業務特化チューニングを伴走型でご支援しています。社内AI導入を検討されている方は、お気軽にお問い合わせください。
参考ソース



