
2026 年春、“自社 MCP サーバー群”が現実的な選択肢になった
2026 年 4 月に入ってから、社内業務を AI エージェントに開放する方法として「自社 MCP サーバー群を持つ」という選択肢が、一気に現実味を帯びてきました。いくつかの動きが重なっています。
- 2026 年 4 月 2〜3 日:New York Marriott Marquis で開催されたMCP Dev Summit North America 2026 に約 1,200 名が集結。MCP ゲートウェイ・gRPC 対応・可観測性など、プロトコル自体の”本番耐性”を高める議論が中心テーマに。
- 2026 年 4 月 9 日:Google が Colab に MCP サポートを正式追加し、ノートブックから MCP サーバーを呼び出して AI エージェントを動かせるように。
- 2026 年 4 月 7 日:Zenn Trending で「社内業務を AI に開放 — 自社 MCP サーバー群一挙公開!」という実践記事がトレンド入りし、国内の情シス・DX 推進担当者のあいだで話題に。
MCP 自体の基本概念については MCP 完全ガイド で解説しているので、「そもそも MCP とは?」の方はまずそちらを読んでから戻ってきてください。この記事は、MCP の存在を知ったあとに、自社で MCP サーバー群を設計・構築・運用するための実務寄りのガイドです。
なぜ「自社 MCP」なのか ── 3 つの動機
パブリック MCP サーバーや SaaS ベンダー提供の MCP を使うだけで済むはずなのに、なぜわざわざ自社で MCP サーバーを構築する企業が増えているのでしょうか。大きく 3 つの理由があります。
- データ主権 社内 DB やファイルサーバーに AI エージェントがアクセスするなら、中継点は自社管理にしたい。監査と権限制御の観点で、情シスの稟議は通しやすくなります。
- ベンダーロックイン回避 「Claude だけ」「Cursor だけ」「Copilot だけ」に閉じた連携を作ると、AI 側を乗り換えたときに全部書き直しになる。MCP を中間レイヤーに据えれば、AI 側と業務側の独立性を保てる。
- 業務に特化したツール設計 汎用 MCP では取り切れない、社内固有のワークフロー(稟議・社内用語・独自 KPI)を、きれいに抽象化できる。
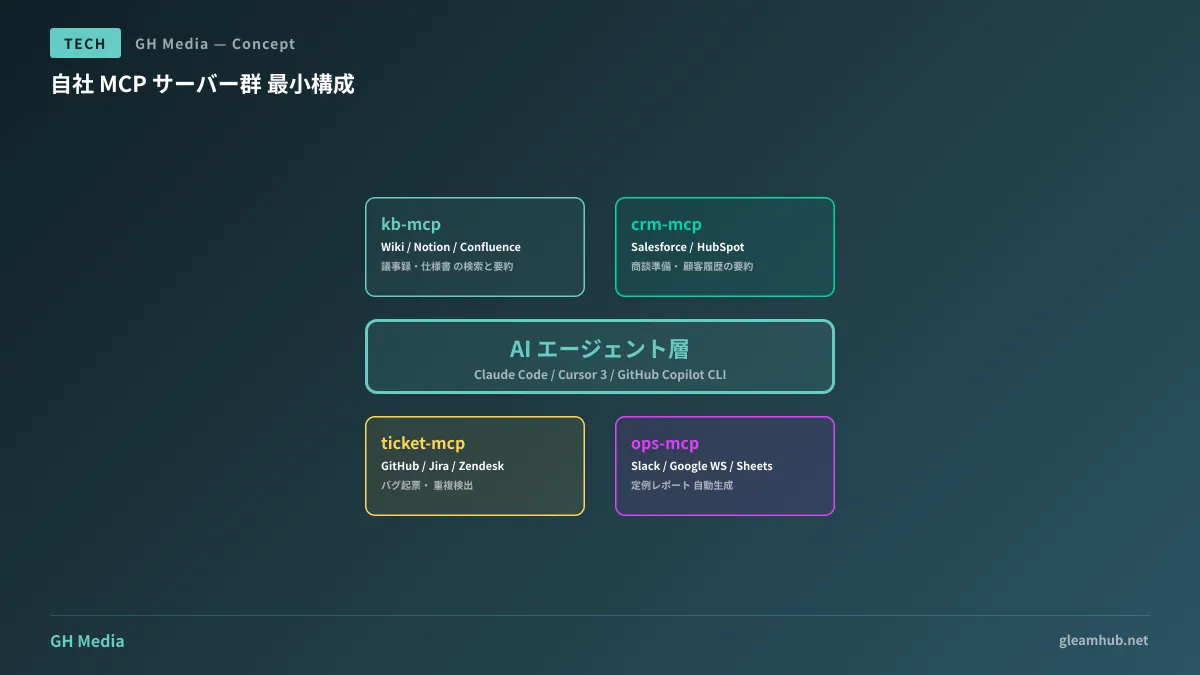
最小構成 ── 最初に作るべき 4 つの MCP サーバー
いきなり”すべての社内システムを MCP 化”するのは現実的ではありません。多くの企業に共通して刺さりやすいのは、次の4 本セットです。
| # | MCP サーバー名(例) | つなぐ先 | ユースケース |
|---|---|---|---|
| 1 | kb-mcp(ナレッジ検索) | 社内 Wiki、Notion、Confluence、SharePoint | 過去の議事録/仕様/契約ひな形を検索・要約 |
| 2 | crm-mcp(顧客情報参照) | Salesforce、HubSpot、自社 CRM | 商談準備、顧客履歴のサマリ生成 |
| 3 | ticket-mcp(開発・サポート) | GitHub Issues、Jira、Zendesk | バグ起票、重複チケット検出、対応履歴の要約 |
| 4 | ops-mcp(業務自動化) | Slack、Google Workspace、スプレッドシート | 定例レポート作成、通知、集計 |
実装言語は TypeScript か Python を推奨します。コミュニティには既に 500 以上のプリビルト MCP サーバーが公開されており、ゼロから書く必要はありません。「プリビルトから開始 → 自社要件でフォーク → 認証層だけ自社実装」が 2026 年時点の現実解です。
サンプル:kb-mcp の最小スケルトン(TypeScript)
// kb-mcp: 社内ナレッジ検索 MCP サーバーの最小例
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { z } from "zod";
const server = new Server(
{ name: "kb-mcp", version: "0.1.0" },
{ capabilities: { tools: {} } },
);
server.tool("search_wiki", {
description: "社内 Wiki を全文検索し、関連度順に返す",
inputSchema: z.object({
query: z.string(),
limit: z.number().default(5),
}),
handler: async ({ query, limit }) => {
// ① 認証コンテキストを取得(誰がリクエストしたか)
// ② 権限に応じてインデックスを絞り込み
// ③ ベクトル検索 + BM25 のハイブリッドで検索
// ④ 結果を構造化して返却
return { content: await searchInternalWiki(query, limit) };
},
});
await server.connect();この 20 行そこそこのスケルトンで、もう Claude Code や Cursor 3 から “社内 Wiki を参照しながらコードを書く” ことができます。驚くほど敷居は低い。
情シスが納得する運用ルール ── 5 項目チェックリスト
MCP は便利な反面、「誰が・いつ・何の権限で・何を実行したか」を説明できない構成だと、稟議・監査・事故対応で確実に詰みます。自社 MCP を構築する前に、以下 5 項目は必ず合意しておいてください。
| # | 項目 | 決めること |
|---|---|---|
| 1 | 認証ポリシー | 社員 SSO 連携(Okta / Entra ID / Google Workspace) |
| 2 | 権限モデル | ロール/属性ベースで、MCP ツール単位・データ行単位の両方を制御 |
| 3 | 監査ログ | 「誰が/いつ/どのツールを/どんな入力で呼び出したか」を永続化 |
| 4 | レート制御・コスト管理 | ツール単位の呼び出し上限、LLM トークン上限、アラート |
| 5 | 禁止業務リスト | 人事評価/個人情報の外部送信/法的判断などの禁止ユースケース |
この 5 項目は ChatGPT Enterprise 組織導入ロードマップ でも紹介した業務 AI 導入ガバナンスと地続きです。業務 AI と開発 AI の両方で同じ枠組みを使うのが、運用負荷を最小化するコツです。
開発会社への発注時に押さえる要件項目
自社で MCP サーバー群を書くリソースがない場合、開発会社への外注になります。その際、RFP(提案依頼書)に最低限書いておきたい項目は次のとおりです。曖昧なまま発注すると、ほぼ確実に後で揉めます。
- 接続先システムの一覧(社内 Wiki、CRM、チケット管理、その他)とアクセス方法(REST / GraphQL / DB 直接)
- 認証・監査要件(SSO、ロール、監査ログ保持期間、SIEM 連携の有無)
- 想定 AI クライアント(Claude Code、Cursor 3、GitHub Copilot CLI、ChatGPT Enterprise など、どこから呼び出すか)
- 可観測性(Langfuse 等の LLM Observability 基盤との連携の有無)
- 納品物(MCP サーバー本体のコード、OpenAPI/MCP マニフェスト、運用ドキュメント、教育資料)
AI 接続側の最新動向は GitHub Copilot CLI の Rubber Duck モード や Cursor 3 徹底比較 にもまとめていますので、どの AI クライアントを前提にするかの選定にぜひ役立ててください。
まとめ
- 2026 年春、MCP Dev Summit・Google Colab の MCP 対応・Zenn の実践記事などが重なり、自社 MCP サーバー群を持つという選択肢が現実的になった。
- 最初に作るべきは kb-mcp / crm-mcp / ticket-mcp / ops-mcp の 4 本。プリビルト → フォーク → 認証層実装、が最短経路。
- 情シスは 認証・権限・監査・レート制御・禁止業務の 5 項目を必ず事前合意。
- 外注時の RFP には接続先一覧・認証要件・想定 AI クライアント・可観測性・納品物を明記する。
GleamHub では MCP サーバーの設計・実装・運用を、社内ガイドライン策定まで含めてワンストップで支援しています。「Claude Code や Cursor を入れたけど、社内データに接続できず本領発揮できていない」という企業のご担当者は、ぜひ一度ご相談ください。



